Train an eCE model
Training an eCE model requires two steps:
Constructing a database: the database contains the configurations and the associated property.
Fitting the model: the model is trained by optimizing a loss function using the PyTorch library.
Construct a database
In order to construct a database, one needs to map the structure onto the ideal lattice and process the data into an object that can be read by the eCE model. The commande data in the ece is meant for constructing a DataBase object from files containing the structure geometries and the properties of interest related to the structure. Arguments must directly be given via the command line interface. The accepted arguments are summarized in the table below.
Argument |
Shortcut |
Type |
Help |
Default |
Notes |
|---|---|---|---|---|---|
|
|
|
Path to the model. |
model.pth |
|
|
|
|
Data containing the path to the file containing the structure, its associated property, and its weight during fitting (optional, default: 1) in every line. |
Use either |
|
|
|
|
Path to a text file containing the paths to the file containing the structure, its associated property, and its weight during fitting (optional, default: 1) in every line. |
Use either |
|
|
|
Maximum deformation allowed in the structure. |
0.2 |
Helps filter out data that are relaxed to another lattice |
|
|
|
Maximum atomic displacement allowed in the structure in Angstroms. |
0.5 |
Helps filter out data that are relaxed to another lattice |
|
|
|
Critical value of the total cost of the mapping to accept. |
0.5 |
Helps filter out data that are relaxed to another lattice |
|
|
|
Weighting factor ([0,1]) for the lattice mapping cost in the total cost calculation. |
0.5 |
||
|
|
Maximum vacancy concentration allowed in the structure. |
0.0 |
Indicates the vacancy concentration range. |
|
|
|
Minimum vacancy concentration allowed in the structure. |
0.0 |
Indicates the vacancy concentration range. |
|
|
|
|
Path to save the processed data in the pickle database format. |
database.pkl |
|
|
|
|
Print information about the processed data. |
False |
Tip
The function can be used in the command line interface when using the ece module. Internally, the module calls the process_data() function. This latter also accepts a dictionary with the same arguments as keys and can be called in a Python script.
data Arguments
model
It specifies the name of the model (and especially the underlying lattice found in the Prim object) to map the configurations onto the same ideal lattice. PyeCE eCE models are saved either as the Pytorch default settings (typically use a .pt or .pth extension) or as a gz-compressed tarfile if the eci model is not built using the from_settings building attribute (use a .tar.gz extension).
data
It contains information about the data to be loaded in the database and expects 2 (3) input arguments as:
-d path_to_structure property (weight)
The
path_to_structureindicates where to find the file containing the structure geometry. Generally, this file corresponds to a VASP POSCAR. However, any file that can be read by Pymatgen is accepted.The
propertycorresponds to the configurationally-dependent property of interest that is intended be infered. The property is expected to be an extensive quantity. In cluster expansion, this property is typically the energy or the formation energy.The
weightis a positive value that is used during training to attach more importance to some data compared to others. The weights are automatically normalized during training. It is thus not necessary to normalize them. The weights are optional and their default values are 1.
This argument can be used several time, once for each data to be included in the database.
batch
The argument refers to the filename of a file containing information about a batch of data to be loaded in the database. The file is expected to have the following format:
path_to_structure_1 property_1 weight_1
path_to_structure_2 property_2 weight_2
path_to_structure_3 property_3 weight_3
... ... ...
Every line contains information related to one data as explained above for the data argument. If weights are specifies for some data, the first line expects at least 2 delimiters to indicate that 3 columns are present.
max_def
The algorithm used to map the structures onto the lattice is a fast method but that relies on the assumption that the deformations of the lattice are small. Under large deformation, the behavior is not well determined. To prevent unpredictable behavior, it is recommanded to filter out structures with deformation larger than a threshold value set by this argument.
Given an ideal lattice \(L\) and the lattice of the structure to be mapped \(L'\), the structure lattice is transformed to the ideal lattice by a deformation as \(L = L' F\). The structure is accepted if:
max_disp
As for the max_disp argument, the algorithm used to map the structures onto the lattice is a fast method but that relies on the assumption that the atomic displacements are small. Under large atomic displacements, the behavior is not well determined. To prevent unpredictable behavior, it is recommanded to filter out structures with atomic displacements larger than a threshold value set by this argument.
Given that both the ideal structure and the structure to be mapped have the same lattice, the atomic displacement of the ith atom is \(\delta_i = |\vec{s'_i} - \vec{s_i}|\), with \(\vec{s}\) and \(\vec{s'}\) are the atomic position of the ideal structure and the structure to be mapped. The structure is accepted if:
max_mapping_cost
A mapping score is computed as in Comparing crystal structures with symmetry and geometry. The mapping cost consists of the contributions of two costs:
Lattice cost: cost based on the deformation matrix to map the child and parent lattices.
Basis cost: cost based on the displacement field to map the child and parent atomic sites.
The mapping cost is computed as a weighted average of those two costs as:
This parameter sets the maximum value allowed for the mapping cost. If the mapping cost exceeds that critical value, the mapping is rejected.
lattice_weight
It specifies the weights associated with the lattice and basis costs to compute the mapping cost.
max_vac
It indicates the maximum vacancy concentration that is allowed in the structure. Vacancies (denoted by Va) must be allowed in the Prim object in case vacancies are expected.
min_vac
It indicates the minimum vacancy concentration that is allowed in the structure. Vacancies (denoted by Va) must be allowed in the Prim object in case vacancies are expected.
name
It specifies the path to save the database in a pickle dataframe format.
verbose
Set it to print information during the mapping of the data.
data Output
As an output, the data functionality creates a DataBase database and save it in the pickle format. The data frame has the following entries for each data contained in it:
The composition: The composition for each species present in the system. For each species corresponds a column named as
x_XxwithXxbeing the symbol of the specie.The number of unitcells: The number of unitcells present in the configuration is indicated in the column named
scel_size.The number of atoms: The number of atoms present in the configuration is indicated in the column named
n_atoms.The property: The value of the property associated to the configuration is indicated in the column named
property.The weight: The value of the weight associated to the configuration during training is indicated in the column named
weight.The lattice mapping cost: The lattice cost to map the lattice of the input structure to the ideal structure is indicated in the column named
lattice_cost.The atomic mapping cost: The atomic cost to map the atomic coordinates of the input structure to the ideal structure is indicated in the column named
atomic_cost.The total mapping cost: The total cost to map the input structure to the ideal structure is indicated in the column named
mapping_cost.The ideal structure: The mapped ideal structure in the format of the string VASP POSCAR file is indicated in the column named
structure.The input structure: The original input structure in the format of the string VASP POSCAR file is indicated in the column named
input_structure.(Optional) The
ConfigData: TheconfigDataobject in the format of a dictionary is indicated in the column namedConfigData.
Fit an eCE model
The fitting process of an eCE model relies on the minimization of a loss function by means of iterative methods such as the Stochastic Gradient Descent (SGD) algorithm. The commande fit in the ece is meant for training an eCE model from a database. Arguments can directly be given via the command line interface or via a YAML settings file. When both arguments are given via the command line interface and via a settings YAML file, the priority is given to the arguments given in the YAML settings file. The accepted arguments are summarized in the table below.
Argument |
Shortcut |
Type |
Help |
Default |
Notes |
|---|---|---|---|---|---|
|
|
|
Path to the model to fit. |
model.pth |
|
|
|
Device to be used for PyTorch operations. |
cpu |
||
|
|
Use cpu device for PyTorch operations. |
Shortcut for |
||
|
|
Use cuda device for PyTorch operations. |
Shortcut for |
||
|
t |
|
Path to the training dataset in pickle dataframe
format of a |
If used, valdidation and test sets can be added
through the |
|
|
|
Path to the validation dataset in pickle
dataframe format of a
|
To be used together with the |
||
|
|
Paths to the test datasets in pickle dataframe
format (allows for several test datasets) of
|
To be used together with the |
||
|
d |
|
Path to the dataset in pickle dataframe format
of a |
If used, it assumes random splitting of the
dataset into training, validation, and test sets
through the |
|
|
|
Proportion of data in the training dataset. |
1.0 |
To be used with the |
|
|
|
Proportion of data in the validation dataset. |
To be used with the |
||
|
|
Proportion of data in the test dataset (allows for several test datasets). |
To be used with the |
||
|
|
List of string slices ‘start:end:step’ (with colon-separations) of indexes of data to include in training dataset (default: start=0, end=len(dataset), step=1). |
To be used with the |
||
|
|
List of string slices ‘start:end:step’ (with colon-separations) of indexes of data to include in validation dataset (default: start=0, end=len(dataset), step=1). |
To be used with the |
||
|
|
List of string slices ‘start:end:step’ (with colon-separations) of indexes of data to include in test dataset (default: start=0, end=len(dataset), step=1). |
To be used with the |
||
|
|
Batch size for each stochastic training step. |
50 |
To be used with the |
|
|
l |
|
List with the number of orbits to include in each ladder training step. |
If not set, one single ladder step including all orbits is performed (default). |
|
|
e |
|
List of the number of epochs for each ladder step. |
[50] |
If only one value is given, the same number of epochs is applied to all steps. |
|
r |
|
List of the learning rates for each ladder step. |
If only one value is given, the same learning rate is applied to all steps. |
|
|
|
List of the learning rates for the embedding matrix for each ladder step. |
If only one value is given, the same learning rate
is applied to all steps. If not specified, the
same value as for the |
||
|
w |
|
List of the weight decays / L2 regularizations for each ladder step. |
If only one value is given, the same weight decay is applied to all steps. |
|
|
o |
|
List of the optimizers for each ladder step where each optimizer is written in string dictionary. |
[‘{“Adam”: {“amsgrad”: true}}’] |
If only one value is given, the same optimizer is applied to all steps. |
|
c |
|
List of the schedulers for each ladder step where each scheduler is written in string dictionary. |
[‘{“ConstantLR”: {“factor”=1, “total_iters”=0} }’] |
If only one value is given, the same scheduler is applied to all steps. The default scheduler results in no change in the learning rate with the number of epochs. |
|
p |
|
List of the earlystopping_patience for each ladder step. |
If no value is set, early stopping is not applied. If only one value is set, it reults in the same early stopping applied to all steps. It requires a validation dataset to be employed. |
|
|
f |
|
Name of the loss function from PyTorch loss functions. |
MSELoss |
|
|
s |
|
Path to a YAML file containing the settings to fit the eCE model. |
||
|
n |
|
Path to save the parameterized model. |
model.pth |
|
|
g |
|
Set it in order to save a log file with the indexes of the datasplit and evaluated errors along the ladder training. |
False |
The generated log file is saved into the same folder as the model (’–name’ argument) with ‘log_fit.json’ basename. |
|
v |
|
Print information about the model. |
False |
Tip
The function can be used in the command line interface when using the ece module. Internally, the module calls the fit_model() function. This latter also accepts a dictionary with the same arguments as keys and can be called in a Python script.
fit Arguments
model
It specifies the name of the model to train. PyeCE eCE models are saved either as the Pytorch default settings (typically use a .pt or .pth extension) or as a gz-compressed tarfile if the eci model is not built using the from_settings building attribute (use a .tar.gz extension).
device
It indicates the PyTorch device to be used during PyTorch operations.
cpu
This argument indiates that the CPU device must be used during PyTorch operations. This is a shortcut to the --device cpu argument.
cuda
This argument indiates that the CUDA device must be used during PyTorch operations. This is a shortcut to the --device cuda argument.
train_file
It specifies the filename of the database containing the training data. All data included in this database are used in the training stage. When this argument is used, it should be used with the valid_file and test_files arguments. It is more convenient to use this method if data need to be split in a controlled fashion.
valid_file
It specifies the filename of the database containing the validation data. All data included in this database are used in the validation stage. This argument should be used with the train_file argument.
test_files
It specifies (possibly several) filenames of the databases containing the test data. All data included in these databases are used in the testing stage. This argument should be used with the train_file argument.
data_file
It specifies the filename of the database containing the all data used during the training process. This database is randomly then split into training, validation, and test datasets. When this argument is used, it is intended to be used together with the train_prop, valid_prop, test_prop, train_indexes, valid_indexes, and test_indexes arguments. It is more convenient to use this method if data are not required to be split in a controlled fashion and/or if several fits are performed with different splits.
train_prop
It indicates the proportion of data that should be included in the training dataset. Proportions do not need to be normalized.
valid_prop
It indicates the proportion of data that should be included in the validation dataset. Proportions do not need to be normalized.
test_prop
It indicates the (possibly several) proportions of data that should be included in the test datasets. Proportions do not need to be normalized.
train_indexes
It specifies indexes data in the database that should be included in the training dataset. When this argument is set together with the train_prop, these data are included after the random split. The argument is expected to be a list string slices start:end:step where start is the first index, end is the last index, and step is the step size. If only one argument is given, it is treated as a single index. If two arguments are given, the step is set to 1 by default. The default start and end are 0 and the last index of the dataset, respecticely.
As an example, given a database with 50 data, the command:
--train_indexes :5 10 20:30:2 40:-3
yields the indexes [0, 1, 2, 3, 4, 10, 20, 22, 24, 26, 28, 40, 41, 42, 43, 44, 45, 46].
valid_indexes
It specifies indexes data in the database that should be included in the validation dataset. When this argument is set together with the valid_prop, these data are included after the random split. The argument is expected to be a list string slices start:end:step where start is the first index, end is the last index, and step is the step size. If only one argument is given, it is treated as a single index. If two arguments are given, the step is set to 1 by default. The default start and end are 0 and the last index of the dataset, respecticely.
As an example, given a database with 50 data, the command:
--valid_indexes :5 10 20:30:2 40:-3
yields the indexes [0, 1, 2, 3, 4, 10, 20, 22, 24, 26, 28, 40, 41, 42, 43, 44, 45, 46].
test_indexes
It specifies indexes data in the database that should be included in the test datasets. When this argument is set together with the test_prop, these data are included after the random split. The argument is expected to be a list string slices start:end:step where start is the first index, end is the last index, and step is the step size. If only one argument is given, it is treated as a single index. If two arguments are given, the step is set to 1 by default. The default start and end are 0 and the last index of the dataset, respecticely. The argument can be used several time to create several test datasets if needed.
As an example, given a database with 50 data, the command:
--test_indexes :5 10 20:30:2 40:-3 --test_indexes 20:30:2
yields the indexes [0, 1, 2, 3, 4, 10, 20, 22, 24, 26, 28, 40, 41, 42, 43, 44, 45, 46] for the first test dataset and [20, 22, 24, 26, 28] for the second one.
batch_size
In order to reduce overfitting and memory overload, the training data are not used all together at onve during an optimization step, but rather an iteration of random “minibatches” of data is performed. This argument sets the size of these minibatches. The training is performed using the PyTorch DataLoader object (see Preparing your data for training with DataLoaders).
ladder_steps
This arguments defines the number of first orbits to include in each ladder training step. No value results in performing one single fit with all orbits at once. Training an eCE model can be challenging as one can easily get stuck in local minima. One solution to help prevent getting stuck in such poor minima is to perform ladder training. This method consists in performing an iterative training starting with a small set of orbits and slowly increasing the number of orbits to eventually perform a fit with all the orbits specified when building the model (see Construction of an eCE model). By default, the orbits are sorted by body-order (number of sites in a cluster) and then by maximum length of the cluster. The strategy is best describes as follows:
Perform a first fit on a set of small, low-body-order, and compact orbits.
Incorporate a few more orbits by increasing their size and body-order and perform a new fit starting from the previous fit.
Repeat the previous point (2.) until all orbits are included.
Below is an example of a ladder training of an eCE containing the first nearest neighbor pair (1NNP), the second nearest neighbor pair (2NNP), the third nearest neighbor pair (3NNP), the fourth nearest neighbor pair (4NNP), and the first nearest neighbor triplet clusters (1NNT). Running the command:
--ladder_steps 2 4 5
results in training the model with the 1NNP and 2NNP orbits in the first ladder step, with the 1NNP, 2NNP, 3NNP, and 4NNP in the second ladder training step, and finally train the model with all orbits (1NNP, 2NNP, 3NNP, 4NNP, and 1NNT) in the last ladder step as pictured in the figure below.
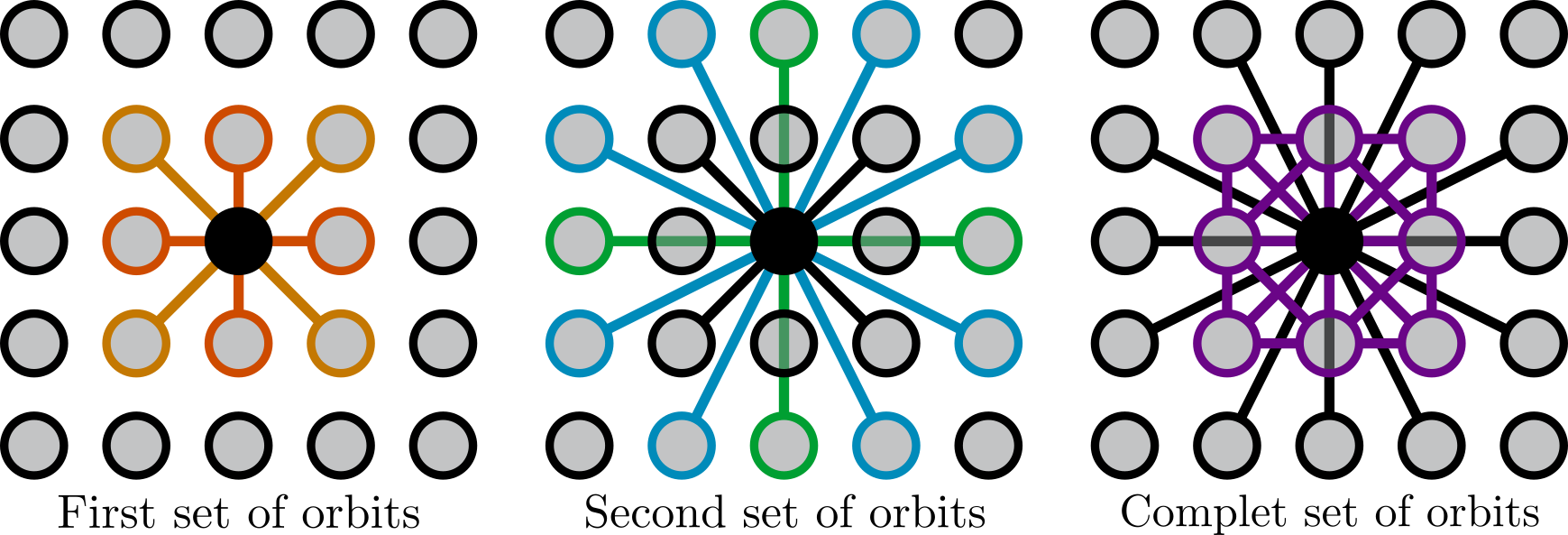
Illustration of a 3-step ladder training where the 1NNP and 2NNp are included first, then the 3NNp and 4NNP are added next, and then all orbits are included in the fitting process.
epochs
It specifies the number of epoch to perform for each ladder step. If only one value is given, the same number of epoch is set to all ladder steps.
lr
It specifies the initial learning rate to use during training for each ladder step (see torch.optim for more information on the optimization implementation in PyTorch). If only one value is given, the same learning rate is set to all ladder steps.
lr_embedding
It specifies the initial learning rate to use during training of the embedding matrix for each ladder step. If only one value is given, the same learning rate is set to all ladder steps. If not the set, the same value as for the lr argument is set. In some cases, using a learning rate for the embedding matrix different (smaller) than that used to train the ECI energy model help prevent getting trapped in a local minimum.
By default, the embedding matrix is initialized by finding similarities between species based on physical/chemcial properties of the pure species (see chemical_preconditioning()). It has been reported that this type of initialization is a fairly good starting point (see Constructing multicomponent cluster expansions with machine-learning and chemical embedding. A learning rate too important might result in going out of the minima in which the initialized embedding matrix was located. For this reason, it is sometimes useful to use different learning rate for the embedding matrix and the ECI energy model.
weight_decay
It specifies the weight decays (i.e., the L2 regularizations) for each ladder step (see torch.optim for more information on the optimization implementation in PyTorch). If only one value is given, the same weight decay is set to all ladder steps. L2 regularization help prevent overfitting by imposing a cost on the L2-norm of the weight. The algorithm optimizes the function \(\mathcal{L}\) defines as:
optimizers
It indicates the optimizers to be used at each ladder step. The optimizers need to be chosen from the list of PyTorch optimizer algorithm. If only one optimizer is given, the same optimizer is used for each ladder step. Because every optimizer has its own set of arguments, the optimizer must be given in the form of a dictionary (or string dictionary in the CLI) where the first level only contains as a unique key the name of the algorthm to be used in torch.optim and specific settings related to the algorithm are found in the next level of the dictionary.
As an example, an ADAM optimizer with amsgrad flag is employed where the default betas and eps are modified:
--optimizers '{"ADAM": {"amsgrad": true, "betas": [0.8, 0.999], "eps": 1e-7}}'
Note
The --lr and --weight_decay parameters could also be directly set here as settings of the optimizer.
schedulers
It indicates the learning rate scheduler to be used at each ladder step. The learning scheduler is a tool to change the automatically change the value of the learning rate as time passes (i.e., as the number of performed epochs increases). It needs to be chosen from the list of PyTorch learning rate schedulers. If only one scheduler is given, the same scheduler is used for each ladder step. Because every scheduler has its own set of arguments, the scheduler must be given in the form of a dictionary (or string dictionary in the CLI) where the first level only contains as a unique key the name of the scheduler to be used in torch.optim.lr_scheduler and specific settings related to the scheduler are found in the next level of the dictionary. The optimizer settings is automatically set from the --optimizers argument.
As an example, a multistep learning rate scheduler (MultiStepLR) is used where the learning rate is multiplied by 0.1 after 55, 85, and 95 epochs in the first ladder step and then a step learning rate (StepLR) is used where the learning rate is multiplies by 0.2 every 30 epochs in the second ladder step:
--schedulers '{"MultiStepLR": {"milestones": [55, 85, 95], "gamma": 0.1}}' '{"StepLR": {"step_size": 30, "gamma": 0.2}}'
earlystopping_patience
It specifies the time to weight before stopping the training in the case the validation loss is not decreasing, i.e., it sets the patience setting in the EarlStopping object, for each ladder step. If only one value is given, the same patience is used for each ladder step. When the validation loss increases, the weight of the best validation loss are recorded so that if the number of epochs with no improvement reached the patience, the model returns to the state with the best validation loss.
loss_fct
It indicates the loss function to be used during training for all ladder steps. The available activation functions can be found in torch.nn. The algorithm optimizes the function \(\mathcal{L}\) defines as:
settings
A path to a yaml file containing all arguments can be given in place of or together with arguments given in the CLI. In case of conflict between arguments given in the settings file and in the CLI, the arguments in the settingsfile have the priority. Missing arguments are set to default values or to the values given in the CLI.
Below is an example of such a settings file. Two test datasets are generated, the first test dataset is randomly generated, while the second contains the last 160 data.
# Datasets
data_file: database.pkl # Path to the database with all data
train_prop: 0.6 # Proportion of data contained in the training dataset (60%)
valid_prop: 0.1 # Proportion of data contained in the validation dataset (10%)
test_prop: [0.3, 0] # Proportion of data contained in the test datasets (30% and 0%)
train_indexes: [':81'] # Indexes of data to be contained in the train dataset (include the first 81 data in the training set)
test_indexes: [[], ['-160:']] # Indexes of data to be contained in the test datasets (include the last 160 data in the second test set)
# Fitting parameters
batch_size: 50 # Batch size for every stocastic step
ladder_steps: # Number of first orbits to include at each ladder step
- 4
- 6
- 8
- 10
- 11
epochs: # Number of epochs to perform at each ladder step
- 100
- 40
- 40
- 40
- 40
lr: # Learning rate to apply at each ladder step
- 0.01
- 0.001
- 0.001
- 0.001
- 0.001
lr_embedding: # Learning rate to apply to the embedding matrix at each ladder step
- 1e-3
- 5e-4
- 5e-4
- 5e-4
- 5e-4
weight_decay: 1e-6 # Weight decay to apply at each ladder step
optimizers: # String dictionary of the optimizer to apply at each ladder step
- Adam:
amsgrad: true
schedulers: # String dictionary of the scheduler to apply at each ladder step
- MultiStepLR:
milestones: [55, 85, 95]
gamma: 0.1
- MultiStepLR:
milestones: [15, 35]
gamma: 0.1
- MultiStepLR:
milestones: [15, 35]
gamma: 0.1
- MultiStepLR:
milestones: [15, 35]
gamma: 0.1
- MultiStepLR:
milestones: [15, 35]
gamma: 0.1
earlystopping_patience: # Early-stopping patience to apply at each ladder step
- 50
- 40
- 40
- 40
- 40
loss_fct: MSELoss # Loss function to be used in the training process
# General settings
name: fitted_model.tar.gz # Name of the trained model
log: true # Create a log file with the training process data
log
This argument indicates whether to save a log file with the indexes of the datasplit and evaluated errors along the ladder training or not. The generated log file is saved into the same folder as the model (’–name’ argument) with ‘log_fit.json’ basename.
name
It specifies the name of the model once it is trained. PyeCE eCE models are saved either as the Pytorch default settings (typically use a .pt or .pth extension) or as a gz-compressed tarfile if the eci model is not built using the from_settings building attribute (use a .tar.gz extension).
The tarfile contains 3 files:
prim.json: a json file to be used construct a
Primobject.ece.pth: a PyTorch file to reload the ECI energy model with the correct architecture.
eCE_state.pth: a PyTorch file to reload the weights of the
eCEmodel.
verbose
Set it to print information during the training of the model.